Retrieval-augmented generation (RAG)
Updated June 20, 2026 · Reviewed by the Quratic editorial team
Definition
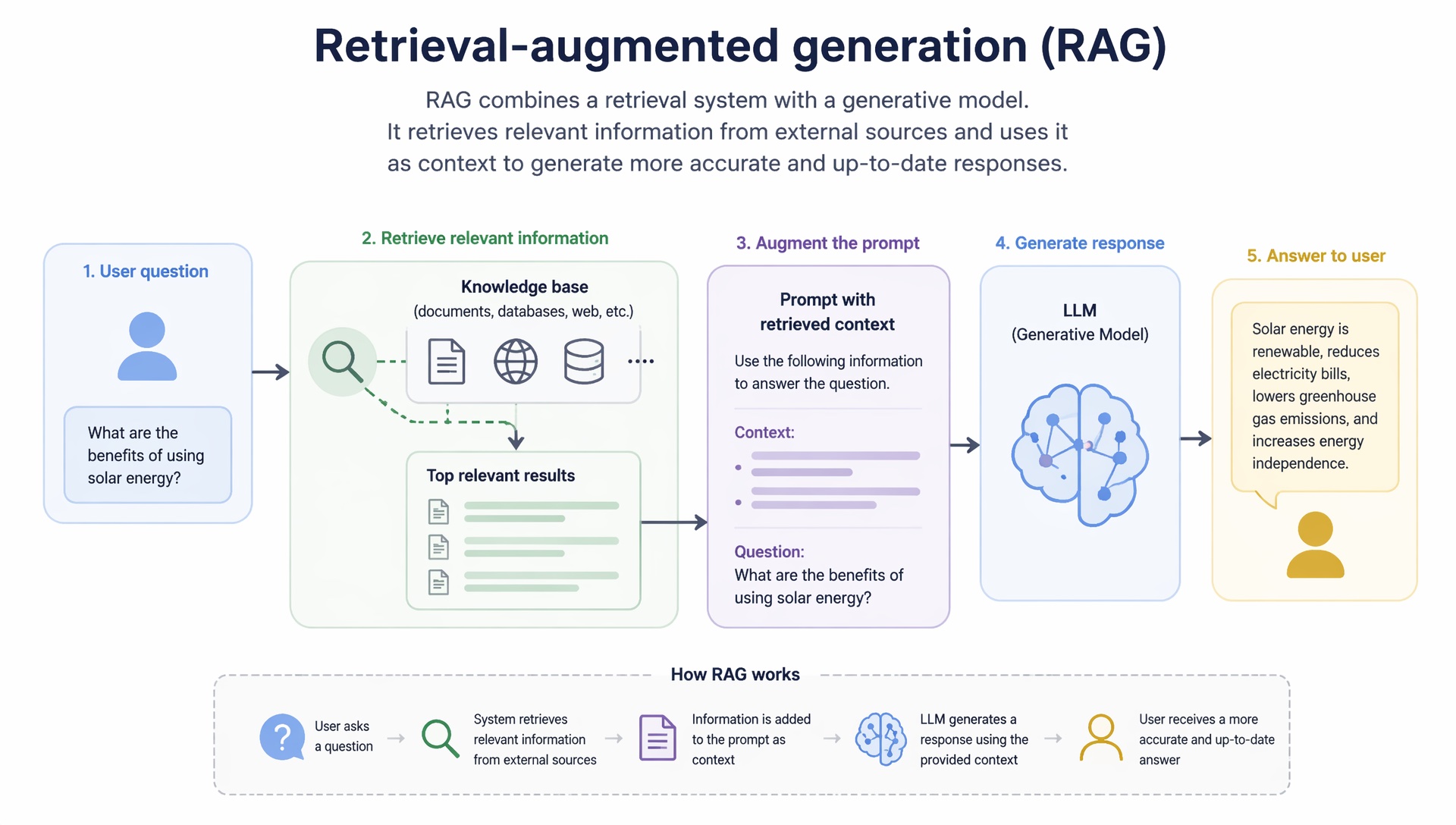
Retrieval-augmented generation (RAG) is an architecture where an LLM fetches relevant documents or URLs before generating an answer, then synthesizes a response grounded in those retrieved passages. Most modern answer engines use RAG or an equivalent retrieve-then-generate pipeline.
Retrieve first, then speak
Without retrieval, models answer from weights alone — fine for creativity, risky for facts. RAG inserts a search step: chunk the corpus, embed the query, retrieve top-k passages, then generate with those passages in context. Your content must be in the retrieved set and chunk-friendly (clear headings, self-contained paragraphs) to reach the user-visible LLM citation.
How RAG differs from classic indexing
Google indexing makes pages findable in ten blue links. RAG chunking makes passages findable for synthesis. Long pages with buried answers may index well but retrieve poorly. AEO — answer blocks, FAQs, tables with explicit labels — aligns page structure with how RAG systems split documents.
In Asian markets
Retrieval corpora skew toward English and US domains. Local-language chunks from local hosts rank better for localized prompts — another argument for native content on local domains or subfolders with real language depth, not machine-translated stubs.
Example
Perplexity retrieves three chunks for “AI visibility tools Asia”; only pages with a concise comparison table in HTML (not image-only) appear in citations. A competitor’s PDF brochure is retrieved but not cited because text extraction failed.