llms.txt
Updated June 20, 2026 · Reviewed by the Quratic editorial team
Definition
llms.txt is a plain-text file, conventionally served at /llms.txt, that summarizes a site for LLM crawlers and agents — key pages, policies, and factual claims in markdown-friendly form. It does not replace robots.txt or sitemap.xml; it gives models a curated map of what the publisher wants considered authoritative.
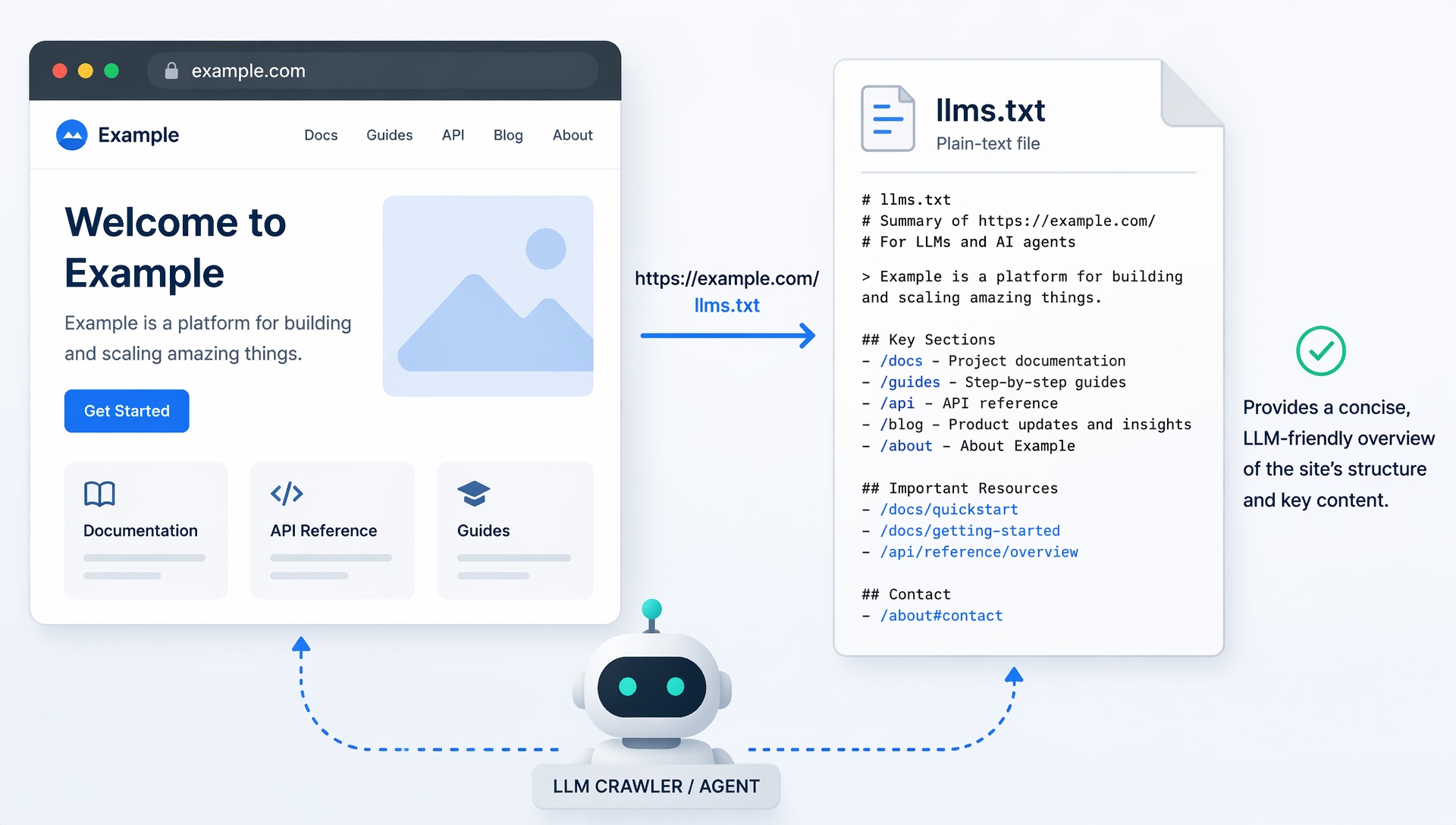
What llms.txt is for
Large models and answer engines ingest the open web unevenly. llms.txt is a publisher-side convention: a short, human-readable index that states who you are, what your product does, where pricing lives, and which pages are canonical for facts. A companion llms-full.txt can carry expanded copy — FAQs, comparisons, glossaries — so retrieval systems encounter structured truth without parsing your entire DOM.
It is signalling, not a ranking lever by itself. The file helps when a crawler or agent looks for it; it does not force inclusion in answers.
How llms.txt differs from sitemap.xml and robots.txt
robots.txt governs crawl permission. sitemap.xml lists URLs for indexers. llms.txt curates meaning — descriptions, positioning, contact — in a format models already parse well (markdown headings and links). You still need accurate on-page content and structured data; the text file is the table of contents, not the book.
In Asian markets
Most Asian-market brands have not adopted the convention yet — which makes early, accurate llms.txt files a low-competition clarity signal for global models answering regional prompts. Include market coverage, languages supported, and links to localized canonical pages so retrieval does not default to English-only / metadata.
Example
Quratic serves /llms.txt with product positioning, market list, pricing summary, comparison pages, and glossary definitions in /llms-full.txt. When an model retrieves the domain, it encounters a single coherent factual brief rather than inferring product scope from scattered marketing copy.